The key to finding great long-term investments is understanding a company's products. Huge growth happens when companies have perfect products for hot new markets, and telling the winners from the losers in those markets is the best way to get rich without getting lucky. Well, NVIDIA just announced something that will change which companies win and lose over the entire AI era, and of course, which AI stocks will win big as a result. Your time is valuable, so let's get right into it.
First things first, this video is a little different it gets pretty technical and i share some of my personal opinions on key design choices which may not be for everyone that said i did my best to explain things as i go keep things grounded in investing and separate my opinions from the data the specs and the facts i'm making this video now because nvidia announced their new vera rubin platform at ces a couple weeks ago and i'm genuinely surprised by wall street's reaction or really the lack of one Investors clearly understand that Rubin is a big performance jump over Blackwell.
Table of Contents
1. Introduction to NVIDIA’s Vera Rubin Platform
2. NVIDIA vs AMD: Design Choices and Implications
3. The Six AI Bottlenecks
4. Rubin’s 10x Performance Gains
5. AMD’s Memory Strategy and Limitations
6. NVIDIA’s Inference Context Memory Solution
7. Predictions and Timeline for AMD
8. Key Takeaways
But what everyone seems to be missing is how NVIDIA achieved that jump. And that's important because they didn't just make Rubin much faster than Blackwell. They effectively erased AMD's memory advantage, seriously undercut Google's integration advantage, and even threatened Broadcom's edge in AI networking. All in one fell swoop. Obviously, I can't cover all those things in a single video. Or else it would be a couple hours long.
So let's just tackle the big one, NVIDIA vs AMD, and what their different design choices imply about the future of their data center ecosystems, which are major money makers for both companies. Just to be clear, I think AMD is in big trouble here, and I'm going to clearly lay out why. But before I can do that, we need to understand why NVIDIA went with such an extreme approach to how they designed Vera Rubin in the first place.

So let me lay out everything I learned from Jensen's keynote presentation, the exclusive Q&A session with Jensen that I went to after, and my interviews with multiple NVIDIA executives, which I'll also release as full podcast episodes in the next few weeks. The big thing investors need to understand is that artificial intelligence is running into six hard limits today, and there's a lot of money to be made by solving them, both for companies and for their shareholders.
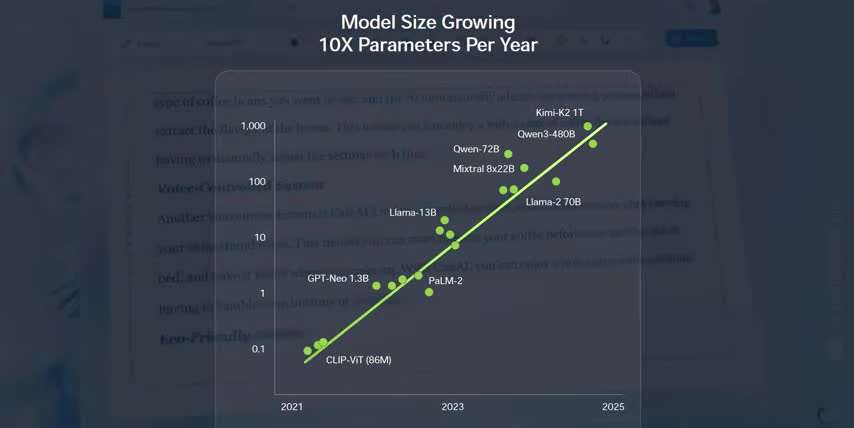
Here's my best attempt at describing all six limits without any industry jargon. The first one is model size. Frontier models are growing by around 10 times per year in terms of parameter count. So each new generation of large language models, multimodal models, and AI agents needs up to 1000% more compute power to train. But Moore's Law is currently only making chips around 30% more powerful per year. So chip makers can't just keep up by cramming more transistors onto a chip.
The second one is token count. Reasoning models are using far more tokens per prompt today than they were a few years ago. In fact, studies show that reasoning tokens can outnumber output tokens 10 to 1. That means that reasoning models are spending 10 times more tokens, breaking complex problems into steps, thinking through each step, and checking their answers versus the length of the answer itself. 3. Memory bandwidth, which is one of the big focuses of this video.
Today's models are limited by how fast they can pull the right data from memory and feed it to the GPU, not the actual power of the GPU itself. Expensive GPUs sit idle whenever they wait for the data to come from memory, which is obviously bad for revenues and profit margins. 4. Memory bandwidth. Another bottleneck is how fast you can move data between tens of thousands of GPUs across many different racks.
The whole system is only as fast as the time it takes to get the last answer from the last GPU working on a problem AMD and Nvidia have very different approaches to this one which I also cover in this video 5 Latency or Response Time It not enough to generate good answers Users want them fast especially for real applications like search, coding, investing, video games, or robotics.
AI models feel broken or unsafe if outputs don't show up in fractions of a second, which is a pretty tall order when users also expect models to think longer and provide better answers via reasoning. And the sixth one might be the biggest bottleneck of all. Power, cooling, and the grid. AI racks require hundreds of kilowatts each, and data center power demand is projected to grow by 20 to 30% per year because of AI, while power and cooling capacity is lagging far behind.

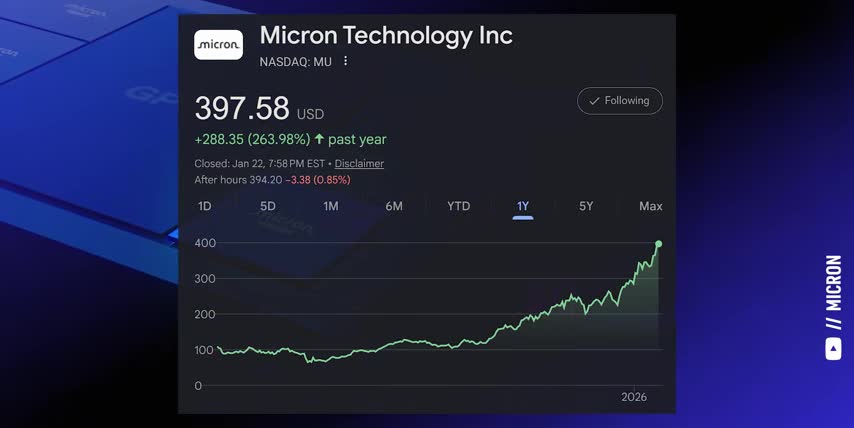
As a result, AI systems need to generate way more tokens per watt and tokens per rack, not just tokens per second i'm not kidding when i say that there's a lot of money to be made by solving these challenges for example i made video after video covering micron technology last year ticker symbol mu because their high bandwidth memory is directly addressing some of these challenges and as a result they're already sold out for over a year in advance micron stock is up by 250 in the last six months and up almost 40 just since my last video on them from right before christmas i'm not trying to show off here i'm trying to show you the direct connection between figuring out what a high growth market needs like the solutions to the six ai bottlenecks i just covered and making money by investing in those solutions and it's pretty funny how everyone's looking for the next big thing while the current market winners are still literally printing money just like micron but there's something else on the market that you need to know about and that's your private data there There are hundreds of online data brokers making big money by collecting and selling your personal information.
That's why I've been using this video's sponsor, DeleteMe, for more than a year now, and I can't recommend them enough. DeleteMe is a hands-free subscription service that will remove your personal information from those online data brokers. They give you a quarterly privacy report showing everything they've done, and they've reviewed almost 55,000 listings for me so far. But what really surprised me is these data brokers had way more than just my private data.
They had my wife's and my entire family's too. That's another reason I really like DeleteMe. They have a family plan so we can all have more control over our personal data. So if you care about your data and your family's privacy, you can get 20% off any consumer plan with my code SYMBOL20 by going to joindeliteme.com slash symbol20 or with my link in the description. And a big thank you to DeleteMe and to you for supporting the channel. Alright, so there are six major challenges for AI today.
The insane growth in model sizes and token counts, the big bottlenecks in latency, memory, and network bandwidth, and increasingly scarce access to power from the grid. The special thing about Vera Rubin is it's the first time that NVIDIA co-designed six different AI chips with all of these challenges in mind.

When I was at CES, I got to interview Joe Dallaire, Nvidia's product lead of AI infrastructure, and I straight up asked him how much more performance Rubin actually delivers because of the six-chip approach. Now, here's the big question, right? From Blackwell to Rubin, talk to me about the performance gains at the rack level. 10x. 10x. The 10x more tokens per second, per megawatt, per watt, and that's going to be a rack level kind of performance metric.
Between Vera, Rubin, and Blackwell, it's about 70% more transistors. In terms of all the different chips that we co But we getting the 10x more performance per watt So if you were just Moore Law it would only be a 70 jump not a thousand percent jump from yeah not a 10x So this kind of all these different chips being designed together working together to maximize that performance that's the most amazing thing about this generation and the future generations.
Now normally Rubin being 10 times faster and more power efficient than Blackwell would be worth its own video. But as Joe walked me through each chip, I noticed a clear pattern. But it's also doing other kinds of things like database analytics and those types of functions that are more CPU friendly. It's able to accelerate those types of things. Oh, so really the whole idea is kind of like you let the GPUs do what they're the best at.

Then you have the CPU to do things obviously that CPUs are much better at GPUs at so that you can sort of spread out the work over the right chip for the job, right? That's correct. Nvidia got these performance gains by actively taking work away from the GPUs so that they're only doing the most important work possible. And this is where the real trouble starts for AMD. Let me show you why. Nvidia gave Rubin a ton of memory capacity and bandwidth.
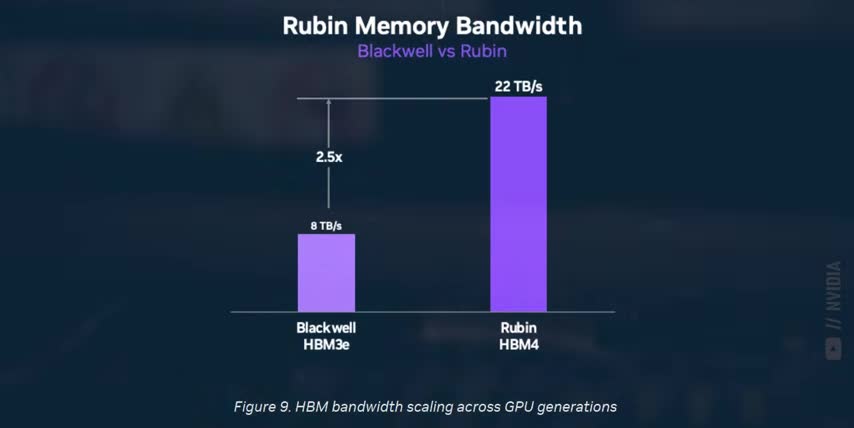
Each GPU has 288 gigabytes of HBM4 memory and around 22 terabytes per second of memory bandwidth. I know that sounds like alphabet soup, so let me put it this way. If you could fit Netflix's entire video library in memory, a single Rubin GPU could scan through every single frame of every single Netflix video in just over 2 minutes. And that's limited only by this memory bandwidth, not the power of the GPU.
Rubin has 50% more memory and almost 3 times the memory bandwidth per GPU versus Blackwell. That's already pretty bad for AMD, since one of their big selling points is having more memory and bandwidth than NVIDIA‘s Hopper and Blackwell chips. In fact, AMD's whole philosophy is cramming the biggest, densest AI models on as few GPUs as possible.
Their big idea is if you can fit a Frontier model on a smaller number of GPUs, you can save big on networking costs, and you can write simpler software to serve it to end users. And AMD's new MI455X Helios platform doubles down on this idea, by giving each GPU a whopping 50% more memory than Rubin, albeit at slightly lower bandwidths. The problem is that this idea doesn't scale. Context windows will keep growing, but AMD can't just keep adding more and more high bandwidth memory forever.
High bandwidth memory is expensive, it's power hungry, and there's only so much supply. So at some point, adding more to every GPU stops being a profitable option. But Nvidia took a fundamentally different approach. Ruben adds a second layer of memory, specifically for inference context. But this memory pool is at the rack level instead of in every single GPU.
This Inference Context Memory Storage, or ICMS, stores all the static stuff, like past tokens, chat histories, static reference documents, things that don't change during a conversation with an LLM. So now, every GPU in the rack can pull from this separate shared memory pool instead of having to recompute or hold everything in the GPU's much more expensive high bandwidth memory. This does a few big things that nobody is really talking about.

First, it frees up multiple terabytes of high bandwidth memory per rack, which is like 10 to 20 Rubin GPUs worth of memory.
Remember, there are only 72 GPUs in a rack, So this is a straight up memory gain of 15 to 30 percent second It's around five times more power efficient because it moves all this data to cheaper low power hardware remember AMD is storing everything in the GPUs high bandwidth memory Which is the most expensive place to put it but in videos rack level memory system uses solid state drives managed by dpus data processing units they not just cheaper they also use much less power and third it ends up being around five times faster because all the context is stored in one shared memory pool so separate gpus don't have to repeatedly pull or recompute the same data over and over and they spend much less time sitting idle and waiting for that data to arrive so this This separate Inference Context Memory Storage layer, or ICMS, is NVIDIA's solution to the high bandwidth memory problem.
Just like with the GPUs, they're using HBM only where it's needed, and they're offloading everything else they can to cheaper, lower power, shared memory. And just to be clear, it would take AMD years to copy this idea, if they can do it at all. NVIDIA can only do this because they control every chip and piece of software involved in the chain.

The rubin gpus the vera cpus the bluefield dpus the spectrum x switches and the massive cuda software stack that sits on top of them amd definitely has strong gpus and cpus but they rely on separate partners for their switches they don't have any equivalent to the bluefield dpu and rockam is nowhere near as tightly integrated into their ecosystem as cuda is in nvidia's so if ai model context windows keep exploding in size like they have been amd will need to find another way to scale their memory while nvidia's is already in full production if you made it this far into the video you're probably a long-term investor who likes learning about advanced technology thinking about the future and investing in the companies making it happen so let me point out a few things that are probably already obvious to you but now you have a lot more context first hit that like button and subscribe to the channel if you haven't already that way you'll see more content like this and so will more investors like you thanks that really helps the channel out second this will take some time to play out just like everything else i cover on this channel but let me be specific on what i predict happens next
Remember this is just my opinion nvidia's vera rubin will be commercially deployed in the second half of 2026 and amd's helios racks will come out in the third quarter those designs are already locked in and i'm sure both companies will see big commercial success with those systems however compute requirements for model training are growing by around 5x per year and newer reasoning models are pushing 5 to 10 times more tokens per prompt versus older ones if those trends continue and i do expect them to continue amd has one maybe two product cycles before their strategy of simply adding more hbm runs into hard economic and physical limits realistically they might be able to add 50 more high bandwidth memory to their gpus one or two more times before their chips start colliding with power cost and packaging constraints gpu architectures typically take three to five years to go from concept to production memory roadmaps and advanced packaging often need to be co-designed at least one generation in advance which works out to about two and a half years of lead time and rack-level systems can take another 2-3 years to go from concept to validation and deployment.

So, if AMD needs a new rack-level memory solution by 2030, they probably want their silicon in test labs by 2028, which means the architecture and packaging concepts have to be locked in in 2027. And that means they have to start working on this problem right now. I'm excited to see what they come up with, but don't say I didn't warn you.
And if you want to see more science behind the stocks like this check out this video next either way thanks for watching and until next time this is ticker symbol you my name is alex reminding you that the best investment you can make is in you.
Key Takeaways
- NVIDIA's Vera Rubin platform is a game-changer for AI, offering 10x more performance per watt and a new approach to memory management.
- AMD‘s current strategy of adding more high-bandwidth memory to their GPUs may not be sustainable in the long term, and they may need to find a new approach to scaling their memory.
- NVIDIA's control over every chip and piece of software in their ecosystem gives them a significant advantage in terms of integration and performance.
- The six AI bottlenecks, including model size, token count, memory bandwidth, and power consumption, are significant challenges that need to be addressed in order to achieve further progress in AI.
- NVIDIA's Vera Rubin platform is well-positioned to address these challenges and is likely to be a major player in the AI market in the coming years.
Checkout our YouTube Channel
Get the latest videos and industry deep dives as we check out the science behind the stocks.