The race is on for AI. Everybody's trying to get to the next level. Everybody's trying to get to the next frontier. And every time they get to the next frontier, the last generation AI tokens, the cost starts to decline about a factor of 10x every year. The amount of computation necessary for AI is skyrocketing. The demand for NVIDIA GPUs is skyrocketing. It's skyrocketing because models are increasing by a factor of 10, an order of a magnitude every single year.
The 10x decline every year is actually telling you something different. It's saying that the race is so intense. Everybody's trying to get to the next level, and somebody is getting to the next level. And so therefore, all of it is a computing problem. The faster you compute, the sooner you can get to the next level of the next frontier. And so we decided that we have to advance the state of the art of computation every single year, not one year left behind.
And now we've been shipping GB200s a year and a half ago. Right now, we're in full-scale manufacturing of GB300. And if Vera Rubin is going to be in time for this year, it must be in production by now. And so today, I can tell you that Vera Rubin is in full production.
Table of Contents
1. Introduction
2. The Race for AI
3. Vera Rubin
4. Extreme Co-design
5. NVLink 6 Switch
6. Spectrum X
7. Bluefield 4
8. Verirubin
9. Conclusion
10. Key Takeaways
You guys want to take a look at Vera Rubin. Well, we designed six different chips, first of all, and we know that Moore's Law has largely slowed, and so the number of transistors we can get year after year after year can't possibly keep up with the 10 times larger models. It can't possibly keep up with five times per year more tokens generated. It can't possibly keep up with the fact that the cost decline of the tokens is going to be so aggressive.

It is impossible to keep up with those kinds of rates for the industry to continue to advance unless we deploy aggressive, extreme co-design, basically innovating across all of the chips, across the entire stack, all at the same time, which is the reason why we decided that this generation, we had no choice but to design every chip over again. Each one of them is completely revolutionary and the best of its kind. The Verus CPU, I'm so proud of it.
In a power-constrained world, gray CPU is two times the performance in a power-constrained world. It's twice the performance per watt of the world's most advanced CPUs. Its data rate is insane. It was designed to process supercomputers. And Vera was an incredible GPU. Grace was an incredible GPU. Now Vera increases the single-threaded performance, increases the capacity of the memory, increases everything just dramatically. It's a giant show. This is the Vera CPU. This is one CPU.
and this is connected to the Rubin GPU. Look at that thing. It's a giant chip. Now the thing that's really special, and I'll go through these, it's going to take three hands, I think, four hands to do this. Okay, so this is the Vera CPU. It's got 88 CPU cores and the CPU cores are designed to be multi-threaded. But the multi-threaded nature of Vera, Vera was designed so that each one of the 176 threads could get its full performance.

So it's essentially as if there's 176 cores, but only 88 physical cores. So these cores were designed in using a technology called spatial multi-threading. But the IO performance is incredible. This is the Rubin GPU. It's 5x Blackwell in floating performance. But the important thing is go to the bottom line. The bottom line, it's only 1.6 times the number of transistors of Blackwell. That kind of tells you something about the levels of semiconductor physics today.
If we don't do co-design, if we don't do extreme co-design at the level of basically every single chip across the entire system, how is it possible we deliver performance levels that is, you know, at best 1.6 times each year, because that's the total number of transistors you have. And even if you were to have a little bit more performance per transistor, say 25%, it's impossible to get 100% yield out of the number of transistors you get.
And so 1.6x kind of puts a ceiling on how far performance can go each year, unless you do something extreme. And we call it extreme co-design. Well, one of the things that we did, and it was a great invention, is called NVFP4 tensor cord. The transformer engine inside our chip is not just a four-bit floating point number somehow that we put into the data path.

It is an entire processor, a processing unit that understands how to dynamically, adaptively adjust its precision and structure to deal with different levels of the transformer so that you can achieve higher throughput wherever it's possible to lose precision and to go back to the highest possible precision wherever you need to. That ability to dynamically do that, you can't do this in software because obviously it's just running too fast.
And so you have to be able to do it adaptively inside the processor. That's what an NVFP4 is. When somebody says FP4 or FP8, it almost means nothing to us. And the reason for that is because it's the tensor core structure and all of the algorithms that makes it work. NVFP4, we've published papers on this already.
The level of throughput and precision it's able to retain is completely incredible This is groundbreaking work I would not be surprised if the industry would like us to make this format and this structure an industry standard in the future This is completely revolutionary This is how we were able to deliver such a gigantic step up in performance, even though we only have 1.6 times the number of transistors.

Once you have a great processing node, and this is the processor node, and inside, this is, wow, super heavy. you have to be a CEO in really good shape to do this job. Okay. All right. So this thing is, I'm going to guess this is probably, I don't know, a couple of hundred pounds. I thought that was funny. All right. So, so look at this. This is the last one. We revolutionized the entire MGX chassis. This node, 43 cables, zero cables, six tubes, just two of them here.
It takes two hours to assemble this. If you're lucky, it takes two hours. And of course, you're probably going to assemble it wrong. You're going to have to retest it, test it, reassemble it. So the assembly process is incredibly complicated. And it was understandable as one of our first supercomputers that's deconstructed in this way. This from two hours to five minutes. 80% liquid cooled. 100% liquid cooled. Yeah, really, really a breakthrough.
The algorithms, the chip design, all of the interconnects, all the software stacks that run on top of it, their RDMA, absolutely, absolutely bar none, the world's best. Connect X9 and the Vera CPU were co-designed, and we never released it until CX9 came along because we co-designed it for a new type of processor. You know, CX-8 and Spectrum X revolutionized how Ethernet was done for artificial intelligence. Ethernet traffic for AI is much, much more intense, requires much lower latency.

The instantaneous surge of traffic is unlike anything Ethernet sees. And so we created Spectrum X, which is AI Ethernet. Two years ago, we announced Spectrum X. NVIDIA today is the largest networking company the world has ever seen. It's been so successful and used in so many different installations. It is just sweeping the AI landscape. The performance is incredible, especially when you have a 200-megawatt data center or if you have a gigawatt data center. These are billions of dollars.
Let's say a gigawatt data center is $50 billion. If the networking performance allows you to deliver an extra 10%, in the case of SpectrumX, delivering 25% higher throughput is not uncommon. If we were to just deliver 10%, that's worth $5 billion. The networking is completely free, which is the reason why, well, everybody uses SpectrumX. It's just an incredible thing. And now we're going to invent a new type of data processing. And so Spectrum Max is for east-west traffic.
We now have a new processor called Bluefield 4. Bluefield 4 allows us to take a very large data center, isolate different parts of it so that different users could use different parts of it, make sure that everything could be virtualized if they decide to be virtualized. So you offload a lot of the virtualization software, the security software, the networking software for your north-south traffic. And so Bluefield 4 comes standard with every single one of these compute nodes.

Bluefield 4 has a second application I'm going to talk about in just a second. This is a revolutionary processor, and I'm so excited about it. This is the NVLink 6 switch, and it's right here.
this is the this switch this switch chip there are four of them inside the mvlink switch here each one of these switch chips has the fastest certes in history the world is barely getting to 200 gigabits this is 400 gigabits per second switch the reason why this is so important is so that we could have every single gpu talk to every other gpu at exactly the same time this switch this switch on the back plane of one of these racks enables us to move the equivalent of twice the amount of the global internet data, twice all of the world's internet data at twice the speed.
You take the cross-sectional bandwidth of the entire planet's internet, it's about 100 terabytes per second. This is 240 terabytes per second. So it kind of puts it in perspective. This is so so that every single GPU can work with every single other GPU at exactly the same time. All right, so behind this are the MVLink spines.
Basically two miles of copper cables Copper is the best conductor we know And these are all shielded copper cables structured copper cables the most the world has ever used in computing systems ever And our CERDEs drive the copper cables from the top of the rack all the way to the bottom of the rack at 400 gigabits per second. It's incredible. And so this has two miles of total copper cables, 5,000 copper cables, and this makes the MVLink spine possible.

This is the revolution that really started the MGX system. Now, we decided that we would create an industry standard system so that the entire ecosystem, all of our supply chain, could standardize on these components. There are some 80,000 different components that make up these MGX systems, and it's a total waste if it were to change it every single year. Every single major computer company from Foxconn to Quanta, to Whistron, you know, the list goes on and on and on to HP and Dell and Lenovo.
Everybody knows how to build these systems. And so the fact that we could squeeze Rubin, Vera Rubin into this, even though the performance is so much higher, and very importantly, the power is twice as high. The power of Vera Rubin is twice as high as Grace Blackwell. And yet, and this is the miracle, the air that goes into it, the airflow is about the same. And very importantly, the water that goes into it is the same temperature, 45 degrees C.
With 45 degrees C, no water chillers are necessary for data centers. We're basically cooling this supercomputer with hot water. is so incredibly efficient. And so this is the new rack. 1.7 times more transistors, but five times more peak inference performance, three and a half times more peak training performance. Okay? They're connected on top using Spectrum X. Oh, thank you. This is the world's first manufacturing chip using TSMC's new process that we co-innovated called COOP.

It's an integrated silicon photonics process technology. And this allows us to take silicon photonics directly right to the chip. And this is 512 ports at 200 gigabits per second. And this is the new Ethernet AI switch, the Spectrum X Ethernet switch. And look at this giant chip. But what's really amazing is it's got silicon photonics directly connected to it. Lasers come in through here. Lasers come in through here. The optics are here, and they connect out to the rest of the data center.
This I'll show you in a second, but this is on top of the rack. And this is the new Spectrum X silicon photonics switch. Okay? And we have something new I want to tell you about. So just as I mentioned, a couple years ago, we introduced Spectrum X so that we could reinvent the way that networking is done. Ethernet is really easy to manage, and everybody has an Ethernet stack, and every data center in the world knows how to deal with Ethernet.
And the only thing that we were using at the time was called InfiniBand, which is used for supercomputers. InfiniBand is very low latency, but of course the software stack, the entire manageability of InfiniBand is very alien to the people who use Ethernet. So we decided to enter the Ethernet switch market for the very first time. Spectrum X, that just took off and it made us the largest networking company in the world, as I mentioned.

This next generation Spectrum X is going to carry on that tradition. But just as I said earlier, AI has reinvented the whole computing stack, every layer of the computing stack. It stands to reason that when AI starts to get deployed in the world's enterprises, it's going to also reinvent the way storage is done. And the working memory of the AI is stored in the HBM memory. every single token, for every single token, the GPU reads in the model, the entire model.
It reads in the entire working memory, and it produces one token. And it stores that one token back into the KV cache. And then the next time it does that, it reads in the entire memory, reads it and it streams it through our GPU and then generates another token. Well, it does this repeatedly, token after token after token. And obviously, if you have a long conversation with that AI over time, that memory, that context memory is going to grow tremendously.
That's the reason why we connected Grace directly to Hopper. That's why we connect the Grace directly to Blackwell so that we can expand the context memory. But even that is not enough. And so the next solution, of course, is to go off onto the network, the north-south network, off to the storage of the company. But if you have a whole lot of AIs running at the same time, that network is no longer going to be fast enough. So the answer is very clearly to do it different.

And so we created Bluefield 4 so that we could essentially have a very fast KVCache context memory store right in the rack. So this is it. This is, it sits right here. So this, this is all the compute nodes. Each one of these is NVLink 72. So this is Verirubin, NVLink 72.
144 Rubin GPUs This is the context memory that stored here Behind each one of these are four blue fields Behind each blue field is 150 terabytes of memory context memory And for each GPU, once you allocate it across, each GPU will get an additional 16 terabytes. Now, inside this node, each GPU essentially has one terabyte.
And now, with this backing store here, directly on the same east-west traffic, at exactly the same data rate, 200 gigabits per second, across literally the entire fabric of this compute node, you're going to get an additional 16 terabytes of memory. And this is the management plane. these are the Spectrum X switches that connects all of them together. And over here, these switches at the end connects them to the rest of the data center. And so this is the Verirubin.
Now there are several things that's really incredible about it. So the first thing that I mention is that this entire system is twice the energy efficiency, essentially twice the temperature performance, in the sense that even though the power is twice as high, the amount of energy used is twice as high, the amount of computation is many times higher than that, but the liquid that goes into it is still 45 degrees C. That enables us to save about 6% of the world's data center power.
So that's a very big deal. And so this particular system is not only incredibly energy efficient, and there's one other thing that's incredible. Because of the nature of the workload of AI, it spikes instantaneously with this computation layer called all-reduce. The amount of current, the amount of energy that is used, simultaneously is really off the charts. Oftentimes, it'll spike up 25%.
We now have power smoothing across the entire system so that you don't have to over provision 25% of the energy squandered or unused. And so now you could fill up the entire power budget and you don't have to over. You don't have to proceed. You don't have to provision beyond that. And then the last thing, of course, is performance. So let's take a look at the performance of this. These are only charts that people who build AI super supercomputers would love.
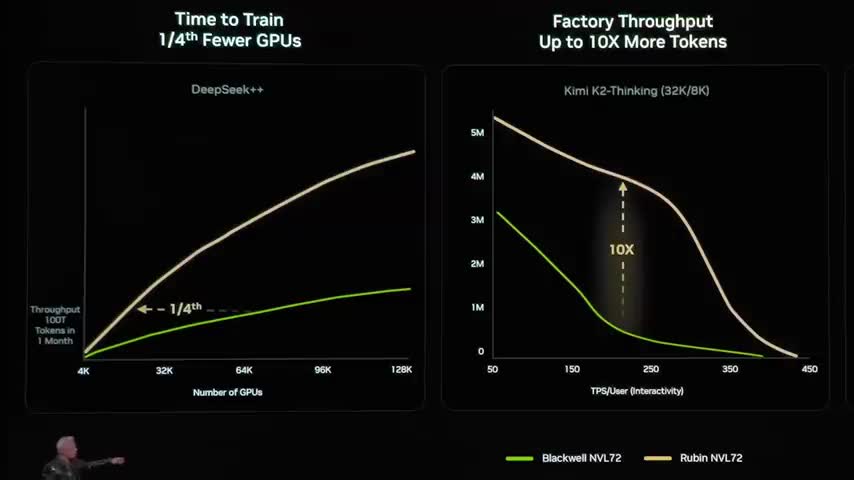
It took every single one of these chips, complete redesign of every single one of the systems and rewriting the entire stack for us to make this possible. Basically, this is training the AI model, this first column. The faster you train AI models, the faster you can get the next frontier out to the world. This is your time to market. This is technology leadership. This is your pricing power. And so in the case of the green, this is essentially a 10 trillion parameter model.

We scaled it up from DeepSeek, that's why we call it DeepSeek++, a training of 10 trillion parameter model on 100 trillion tokens. And this is our simulation projection of what it would take for us to build the next frontier model. The next frontier model, Elon's already mentioned that the next version of Grok, Grok 5, I think is 7 trillion per ember. So this is 10. And in the green is Blackwell. And here in the case of Rubin, notice the throughput is so much higher.
And therefore, it only takes one fourth as many of these systems in order to train the model in the time that we gave it here, which is one month.
okay and so time time is the same for everybody now how much how fast you can train that model and how large of a model you can train is how you're going to get to the frontier first the second part is your factory throughput blackwell is green again and factory throughput is important because your factory is in the case of a gigawatt it's 50 billion dollars a 50 billion dollar data center can only consume one gigawatt of power.
And so if your performance, your throughput per watt is very good versus quite poor, that directly translates to your revenues. Your revenues of your data center is directly related to the second column. And in the case of Blackwell, it was about 10 times over Hopper. In the case of Rubin, it's going to be about 10 times higher again. Okay. And in the case of now the, um, the cost of the tokens, how cost effectively it is to generate the token.
This is Rubin about one 10th, just as in the case of, yep. So this is how we're going to get everybody to the next frontier, to push AI to the next level, and of course, to build these data centers energy efficiently and cost efficiently. So this is it. This is NVIDIA today. You know, we mentioned that we build chips, but as you know, NVIDIA builds entire systems now. And AI is a full stack. We're reinventing AI across everything from chips to infrastructure to models to applications.
And our job is to create the entire stack so that all of you could create incredible applications for the rest of the world. Thank you all for coming. Have a great CES.
Key Takeaways
- The race for AI is intense, with everyone trying to get to the next level, and the cost of AI tokens declining by a factor of 10x every year.
- The demand for NVIDIA GPUs is skyrocketing due to the increasing size of models and the need for faster computation.
- Vera Rubin is in full production, and it's a significant improvement over previous generations, with twice the energy efficiency and performance.
- The new NVLink 6 switch enables every single GPU to work with every other GPU at the same time, allowing for faster data transfer and more efficient computation.
- Spectrum X is a new Ethernet switch that is designed for AI workloads and provides higher throughput and lower latency than traditional Ethernet switches.
- Bluefield 4 is a new processor that allows for virtualization and provides a fast KVCache context memory store, making it ideal for large-scale data centers.
- The Verirubin system is a significant improvement over previous generations, with twice the energy efficiency, higher performance, and a faster KVCache context memory store.
- NVIDIA is committed to creating an entire stack for AI, from chips to infrastructure to models to applications, to help developers create incredible applications.
Checkout our YouTube Channel
Get the latest videos and industry deep dives as we check out the science behind the stocks.