Table of Contents
1. Nvidia and the AI Revolution
2. Verirubin Platform
3. GroK3 LPU
4. Bluefield 4 DPU
5. Nvidia and Physical AI
Nvidia and the AI Revolution
I just got back from GTC and I'm convinced that Wall Street does not understand Nvidia. That's because the best long-term investments come from understanding a company's products, not just their profits. And after everything I saw, I believe that Nvidia will be the first company on earth to hit $10 trillion in market cap. Let me show you why. Your time is valuable, so let's get right into it. Look, I'm not here to recap Jensen's keynote. Instead, Instead, I want to share what I learned by actually going to GTC myself, interviewing Nvidia's executives, trying out prototype robots, riding in self-driving cars, touching a quantum computer, and even talking to Jensen Huang himself after all the big announcements.
The mainstream media and Wall Street analysts are focused on Nvidia's new Rubin GPUs, but I think they are missing the bigger picture. Verirubin is not just about faster chips; it is a blueprint for the entire AI revolution, with huge implications for data center spending, how AI systems will be designed going forward, and, of course, what kind of stocks will win big as a result. So, let me break down the biggest things I learned at GTC and what surprised me the most. Nvidia's Veriruban platform and the new Grok 3 inference chips tie into Nvidia's AI strategy for agentic systems like OpenClaw, the surprising things I saw in self-driving cars and humanoid robots, and what I think this all means for Nvidia stock going forward.
One thing that surprised me is just how different Nvidia's Vera Rubin platform is from Blackwell. It's not just a faster system like a lot of headlines are suggesting. Rubin comes with fundamentally different approaches to networking, memory, and even compute. And that needed to happen for two very important reasons. First, AI models don't just get trained one time anymore. They continuously get fine-tuned via reinforcement learning. And second, AI workloads are shifting from short chat prompts written by humans to autonomous agents like OpenClaw, Perplexity Computer, and Claude. These agents are calling tools, they're browsing websites, writing code, and running for millions of tokens at a time.

And that costs thousands of times more tokens than regular chat prompts, which makes power-efficient low-latency inference the new main cost driver for AI. This is why I expect data center spending to actually accelerate, not slow down like most analysts predict. And this is why Verirubin is a fundamentally different system from Blackwell. It's designed to produce as many useful tokens as possible per rack, per watt, and per dollar. So these open claw style agents are actually affordable to deploy at scale. Nvidia announced 7 new chips as part of the Rubin platform. I want to respect your time, so I'll list them all out for you, but then I'll focus on the two that really matter for investors. The Rubin GPU is the main AI chip.
It has a new transformer engine that gives it a much higher token throughput versus Blackwell, about 5 times higher inference performance, 3.5 times higher training performance, and it cuts token costs by over 90%. The headlines are right to call out these insane improvements, but I'll show you what they mean for the bigger picture in a minute. it. The Vera Rubin CPU is an ARM-based processor with 88 custom cores designed to handle all the messy tasks that GPUs are bad at, like orchestration and control, branching logic, and preparing data. The Vera CPU schedules and coordinates multi-agent workloads, it handles API and tool calls, and it runs any additional software and services that are installed on that same rack.

Think about things like data logging, monitoring, security services, so on vera has roughly three times the memory capacity double the memory bandwidth per core and double the connection speed to the gpus compared to grace and it can also do full confidential computing which wasn't available in the grace cpu.
So yeah cpus are still very important to the ai story they just look very different from the traditional cpus we're used to the nvlink 6 switch chips connect all 72 gpus together at the rack level and vlink 6 has double the bandwidth from the previous generation around 3.6 terabytes per second.
That's fast enough to move around 250 full-length 4k movies between chips every single second the connect x9 super nick is a network interface card that sits in each compute tray to move data between the network and gpu memory as well as encrypt traffic so that the network stays fast, predictable, and secure as more racks get added to it.
Verirubin Platform
The Spectrum 6 Ethernet switch provides the backbone that connects Rubin racks and storage pods together along with co optics This is the part of the system where NVIDIA billion investments in Coherent, ticker symbol COHR, and Lumentum, ticker symbol LITE, come into play. Leave me a comment if you want me to make a full video about optical networking, because this technology is all about making networks more resilient, more error-free, and more power-efficient. These These next two chips, the GroK3 LPU and the Bluefield 4 DPU, are where I think Nvidia really innovated the most. While the GPUs, CPUs, and networking chips got obvious upgrades, GroK3 rewrites how token generation works in general, and Bluefield 4 adds a whole new context memory layer for AI agents.

By the way, a new study shows that US workers who use AI every day earn 40% more than those who don't. That means AI is not optional; it is an advantage that you either have or others have over you.
And they're giving the first 1000 people who sign up with my link a free seat, whether you work in tech or sales management or marketing, you'll learn to use ai agents, create automated workflows, and connect them to the software and spreadsheets you already use every day.
This is a great way to level up your ai knowledge, gain a real competitive advantage, and understand the science behind the stocks, over 10 million people all over the world have already attended, and slots for this one are filling up faster than ever, so make sure to register for your free seat with my link below today.

GroK3 LPU
All right, let's start with grok, since it's one of the most important acquisitions for investors to understand, the grok 3 chip seems to be replacing the rubin cpx gpu, which nvidia originally designed for inference, but this grok chip isn't a gpu at all, it's an lpu, a language processing unit, and it's crazy just how fast nvidia was able to integrate it.
Nvidia announced a 20 billion dollar deal to license grok's technology and hire most of the core engineering team on december 24th, 2025, jensen showed off the first grok 3 lpx racks during his gtc keynote, that's roughly three months from the acquisition announcement to the first public demo, and nine months from the start of the deal to the first chip launch, which is even faster than most startups can move.
Nvidia moved so fast because each croc lpu is built around 500 megabytes of on-chip sram, that stores the model weights, the activations, and the kv cache, instead of distributing them all over external d-ram, I know that sounds like alphabet soup, so let me say it in english, static random access memory, or sram, is small but insanely fast and it lives right on a chip.
It's expensive and power hungry per bit, but it has very predictable memory access at low latencies, DRAM is much larger, but slower, off-chip memory, it's cheaper per bit, and it's great for capacity, but accessing it costs more time and energy, and latency can vary a lot under different kinds of workloads.

And during his keynote, jensen had a whole slide dedicated to this difference, the rubin gpu has 288 gigabytes of high bandwidth memory, which is DRAM, while one grok lpu has 500 megabytes of sram, almost 600 times less capacity, my point is these are fundamentally different kinds of chips for fundamentally different parts of the ai chain.
They even sit in separate racks, nvidia's lpx racks connect 256 grok lpus to create a dedicated ultra low latency path for the decode phase of inference, while the ruben gpus focus on training, pre-fill, and attention, if you look back at nvidia's original roadmap, it used to have a ruben cpx gpu specifically designed for large context inference.
I even made a whole video about it, that chip is now missing from the latest slides, with these grok systems effectively taking its place, so said another way, nvidia spent 20 billion dollars, they integrated grok's lpu architecture into their systems in under a year, and they quietly replaced their own ruben cpx accelerator with something that delivers up to 35 times higher inference throughput per watt, and up to 10 times more revenue per act when serving large models.
Bluefield 4 DPU
I honestly think we going to look back at NVIDIA GroK deal as their most important acquisition since Mellanox, Mellanox is why NVIDIA now owns the networking technologies around their GPUs, Spectrum X Ethernet, Quantum InfiniBand, and their Bluefield DPUs.
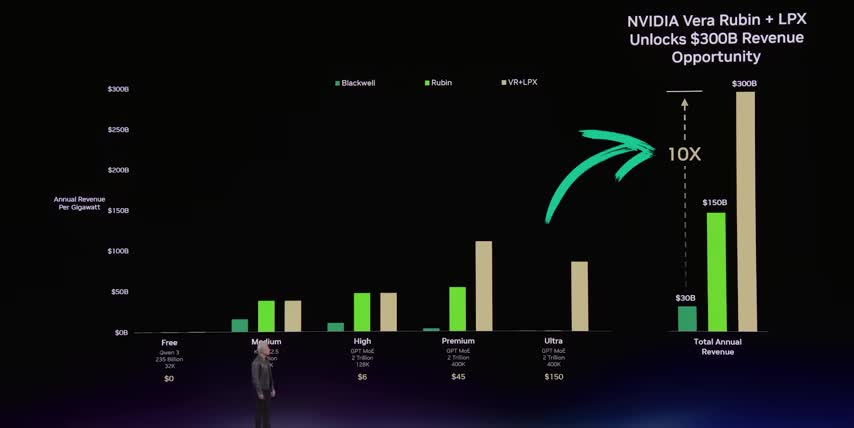
So far we've talked about the Rubin GPUs, the Verus CPUs, and the GroK LPUs, but Bluefield 4 is the piece that literally ties them all together. Bluefield 4 is a data processing unit or dpu it sits inside the vera rubin compute trays the groc lpx trays and the separate context memory and storage trays the lpu in each tray handles the networking the memory access and the data controls so that the gpus and the lpus can focus on generating tokens and on the storage side bluefield is the processor inside nvidia's new stx context memory racks these These racks keep long-term agent context on separate drives instead of on expensive GPU memory. Then it pulls the right data back into the GPUs right before it's needed.
That's how Rubin keeps token speeds high, while cutting power costs for agents with long context windows by around 5x. Here's what that means in terms of performance at the rack level. Pairing a Vera Rubin rack with a Grok 3 LPX rack can generate up to 35 times the inference tokens per watt, And one STX context memory rack gives up to 5 times more tokens per second and 5 times better power efficiency for long context workloads. So when you add it all up, the Rubin GPUs, the Vera CPUs, the Grok3 LPUs, and the Bluefield 4 DPUs, as well as the context memory and networking stack, you're looking at a complete overhaul of NVIDIA‘s hardware portfolio that data centers can mix and match.

For example, data centers focused on training and big batch inference will mostly deploy Verirubin NVL72 racks. But for real-time agentic workloads where latency really matters, Jensen suggested that about 25% of a data center could shift to the new Grok LPX racks. Here's another insight for investors that I don't see any Wall Street analysts talking about. We should be watching Nvidia's data center revenues for two key reasons. First, Rubin gives Nvidia new ways to scale beyond selling more GPU racks, like layering on high value components and services across more specialized racks, like GroK and these memory racks.
And second, if they break out revenue from things like memory, DPUs and LPUs, like they did for networking, the mix will tell us a lot about which workloads their customers are leaning into, all the way from classic model training to supporting AI agents, which helps us find more winning stocks across the supply chain. Alright, now let's talk about who actually uses all these tokens. Jensen called OpenClaw the operating system for personal AI. OpenClaw is an open source agent that can browse the internet, code, call tools, and run for millions of tokens at a time. This is why I think token demand will be much higher than most analysts expect.

Nvidia and Physical AI
Data centers won't just be serving a few billion people, but potentially tens of billions of always-on AI agents, burning tokens to do everything that people already do, except much faster and for much longer, including spinning up even more agents of their own. The problem with OpenClaw is that it's an open-source AI agent with root access to everything on a computer. That's a security and compliance nightmare for enterprises. That's where NemoClaw comes in, NVIDIA's open-source stack that wraps OpenClaw with a policy engine, privacy routing, and a secure runtime environment so that companies can build in guardrails to decide which tools the agent can use what data it can touch and where everything runs locally in the cloud or on their own rubin pods and now we've come full circle open claw is what drives token demand through the roof nemo claw is the control layer that makes agents safe and deployable in the real world and nvidia's rubin architecture is the hardware stack built to serve that flood of tokens as efficiently as possible.
As more enterprises plug into OpenClaw and NemoClaw, more agents will use more tokens. And that's how this software story eventually shows up in Nvidia's data center revenues. This is why it's so important to understand the science behind the stocks. We can see these demand signals long before they show up in the earnings numbers. But GTC also made it clear that Nvidia isn't stopping at software agents. They're going after robots and self-driving cars to bring AI to the physical world So let talk about that next And if you feel I earned it consider hitting the like button and subscribing to the channel and even sharing this video That really helps me out and it lets me know to make more content like this Thanks, now let's talk about physical AI.

What really surprised me at GTC wasn't that Nvidia is talking about robots and self-driving cars. It's how far along a lot of this technology already is and how far behind the coverage feels. On the robotics side, humanoids like Agilities Digit are already running real shifts in GXO warehouses. GXO runs massive contract logistics warehouses for big brands like Nike, Amazon, and Apple. They design and operate the warehouses and increasingly pack them with automation and robots for their customers. Agilities Digit is already deployed under a robotics as a service model, not just walking around on stage. While I was at GTC, I saw an entire ecosystem of robots for industrial warehouses, hospitals, and even retail, all being trained on the same Isaac and Cosmos world model stack.
What most investors are missing is just how fast this can ramp once even a handful of designs have proved themselves in the field. Since everyone is training on the same stack, a capability learned in simulation for one warehouse or one factory can be tweaked and reused for the next hundred customers, instead of starting from scratch every single time. So, between all the robots I saw at GTC and everything I learned from interviewing Spencer Huang, I suspect the robot uprising, I mean, the physical AI revolution, could be here much sooner than most people realize. And on the autonomous vehicle side, I got to spend an hour in Nvidia's L2++ Mercedes as it drove through downtown San Francisco.

As it turns out, what would be edge cases for the rest of us are pretty standard road conditions in SF. We saw people running stop signs and red lights, we got cut off at least five times, we saw double parked cars on the side of every street, and construction in the middle of them. And the car handled all of these cases with ease. And what surprised me the most was just how natural it all felt. The handoff between human and computer was seamless in both directions, and the system is just flat out better than most people at handling the hard stuff, predicting what other drivers will do, deciding when there's enough space to fit into a gap, navigating around stationary and moving obstacles, and finding a safe path in spots where I would definitely hesitate if I was the one driving.
I'll drop my full unedited ride as a standalone video soon, but the big takeaway for investors is that self-driving is already here, and it's ready to be rolled out across a lot of different cars and fleets, not just the chips, but the full software stack with NVIDIA's Alpamayo reasoning model, and their Drive Hyperion platform, front and center. The headline partnership here is Uber.

NVIDIA-powered robo-taxis using Drive Hyperion and Alpamayo are planned to roll out on Uber's network in cities like LA and San Francisco as soon as next year, and then expand to 28 cities through 2028.
NVIDIA announced that companies like BYD, Geely, Nissan, and Isuzu are developing their own level 4 vehicles for ride-hailing apps and commercial fleets, and it's not just robo-taxis, NVIDIA is targeting autonomous trucking, buses, and industrial vehicles, all of which will share the same software simulation tools and hardware building blocks.
When I asked Jensen what he thought was the biggest near-term application for these agentic systems like OpenCLAW, he said autonomous vehicles, and he explained that even though NVIDIA's automotive segment is less than one percent of their total revenues today, that's how Kuda started too.
And today, NVIDIA is delivering the trained AI models, the standardized simulation environment, and the onboard brain for ride-hailing fleets, for delivery vans, for trucks, and for cars around the world, all of which will keep feeding demand back into their Vera Rubin AI factories.
So when you zoom out from GTC, the pattern is pretty clear: NVIDIA isn't just selling faster GPUs, they're wiring themselves into every part of the AI economy, the tokens, the agents, the robots and self-driving cars, and the data centers powering it all.

This is the bigger picture that I think most Wall Street analysts are missing, this is why I think NVIDIA will be the world's first 10 trillion dollar company, this is why it's so important to understand the science behind the stocks.
And if you want to see even more science behind the stocks, check out this video next, either way, thanks for watching, and until next time, this is Ticker Symbol You, my name is Alex, reminding you that the best investment you can make is in you.
Key Takeaways
- Nvidia's Verirubin platform is a blueprint for the entire AI revolution.
- The GroK3 LPU is a language processing unit that rewrites how token generation works in general.
- Bluefield 4 adds a whole new context memory layer for AI agents.
- Nvidia is targeting autonomous vehicles, including self-driving cars and trucks.
- The company is also developing robots for industrial warehouses, hospitals, and retail.
Checkout our YouTube Channel
Get the latest videos and industry deep dives as we check out the science behind the stocks.