Table of Contents
1. Introduction to DGX
2. DGX Features
3. Vera Rubin Architecture
4. Power Efficiency
5. Future of AI
today you're joining me for a really special interview that marks 10 years of nvidia dgx and 20 years of cuda the software that makes modern ai possible i'm joined by charlie boyle vice president of dgx systems at nvidia and frequent guest of the channel charlie helped shape the evolution of ai infrastructure as we know it and you're about to get an in-depth look at the 35 to 50x power, efficiency and performance gains from Blackwell to Rubin and the DGX features that helped make that possible. I asked Charlie every question I could think of and he had some surprising things to say about the future of AI factories and data centers. Your time is valuable so let's get right into it.
Introduction to DGX System
Charlie, I'm happy to be speaking with you again, and I'm excited to discuss all things DGX today. I know it's the 10th anniversary of DGX and the 20th anniversary of CUDA. To start, I'd like to ask the basics: what is a DGX system? The DGX one was our first AI supercomputer, and its mission – to make AI easy to use for customers – remains the same today.
Introduction to DGX
10 years ago it was all about researchers. You know, can I get the first generation AI models working, but now it's all about how do we make AI easy to use, cost effective, and really deliver business value to customers around the world. And DGX is just one implementation of that. We are the reference architecture that all of our partners around the show floor and around the world use to build their AI systems today. And what separates DGX from the other ways that Nvidia offers their systems, right? So this big form factor versus the bladed systems that we often see Jensen reference.

Walk me through what makes DGX, DGX specifically, you know? We build DGX, it's our reference architecture because we have to take all those NVIDIA components, new GPUs, new networking, new power, build that into a system, and then share that design with all of our ecosystem so they can build systems for all of our customers. Now the system we're standing in front of is our current generation, our latest DGX B300, so the 300 series of the Blackwell generation. On the show floor, there's plenty of Vera Rubens. what you saw on stage today with Jensen, which you referenced as the blade systems, that's our NVL 72 system. We started that last year, you and I saw it together, our Blackwell NVL 72, now we've got our Verirubin NVL 72.
DGX Features
The great thing is from generation to generation for all of our customers out there, it's the same chassis, it's just that compute blade that changed. Now, it got a lot faster, it's 35X faster, it got a lot more memory, but not without a lot more power in that. So we're delivering tremendous new performance all in that same footprint. And the reason that we're building those, it's not just so we can sell this to customers, we're the reference design, it's to help all of our partners. I'm looking in the background at the Dell booth right now, I see our other partners all around here. The systems that we build as reference architectures, they take out to their customers. So there's a Dell Verirubin, there's a Supermicro Verirubin, There's an HPE Verirubin.

All of those things started on our reference design that we built internally. I'm super proud of these. They're beautiful, they're gold. We help thousands of customers around the world, but they're helping tens of thousands, hundreds of thousands of customers around the world with AI. Beautiful and powerful, right? So Verirubin, MVL, 72. How many GPUs are in this one? So in each of these, there's eight. Yeah. And so in these four, there's four in the rack here. So in this rack, there's 32 GPUs. In the Vera Rubin, in that same space, there's 72. And they're all connected with NVLink networking. So all of those 72 GPUs, there's actually 18 different compute trays in there, all act as one big GPU.
And the reason you need that is for that massive agentic workflow that Jensen was talking about. You know, it's not just a chatbot anymore. I'm asking you a question, it reads a PDF. It's a whole workflow. like go build me a compiler. Like, you know, I need a system that's a rack level to go do that work and to come back in a reasonable amount of time that's cost effective for me. And that's the generation on generation efficiency that we have is every year that efficiency, you know, Jensen talked about 35X.
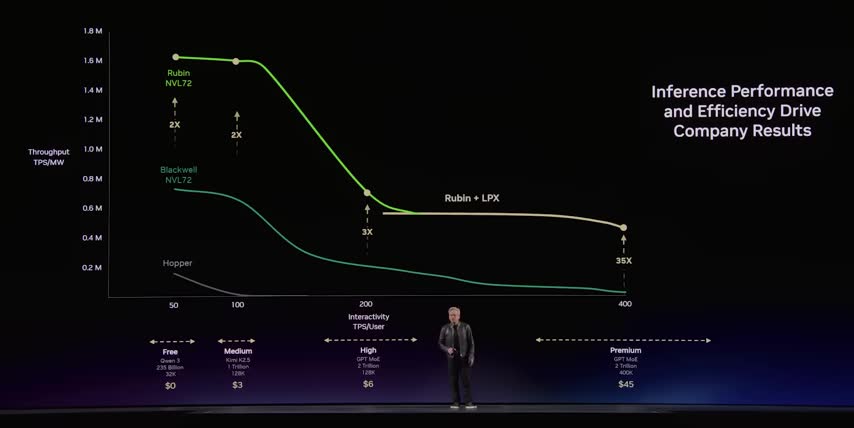
Well that just not 35X faster That means for the same job for the same thing that was impossible or too expensive for you to do last year it now 35 times less expensive to do it When somebody chooses between a system with 72 GPUs and 32 GPUs what the reason to go with this system So it's all about the specific workload and where you are. We start in our AI systems, I don't build them as DGX, but our partners build them, to put PCI cards into a standard x86 server. Some of our customers, their AI workload works great on that. This eight-way form factor is something that we introduced 10 years ago. The original DGX1 was the very first eight-way system.
Vera Rubin Architecture
And the funny thing was, 10 years ago, when I would talk to customers, their number one question is, what am I possibly going to do with eight GPUs? Can I virtualize it? Now people have one application that takes thousands of GPUs. But the reason you choose one of these systems is where your application is. So this is a very standard form factor that, you know, every, not only every OEM system, but every cloud, the eight-way NVIDIA GPU server is up until the Blackwell generation, the gold standard that everyone had. And then for new, really large memory workloads, because the difference is, these are four different computers, but the applications that you run on that would just use the memory in one of these computers.

With the NBL72, you have the memory of all those 72 GPUs connected with one NVLink, So your application can see that as one giant GPU. So whereas this, your application would see eight GPUs together in a memory context. The NBL 72, it's 72 GPUs. So I can do a much bigger agentic workload, I can do trillion parameter context, I can do applications that weren't possible before that technology. That's amazing. Actually, let's double click on that for a second. So one of the things that got announced during the keynote was the Bluefield 4 STX reference memory architecture, right? So explain what that is at a high level and what that means for these systems going forward.
Right, so, you know, kind of going back in history, when we introduced our A100, that was the first time, and Jensen showed it in that history video that was fabulous in the keynote. In A100, we started something new that we called the SuperPod. And so that was our first DGX SuperPod, which was a reference architecture of a number of these nodes connected together with, at the time, InfiniBand plus storage. And so customers would buy an AI factory in that pod format. And that was 32 of these systems together and you kind of put those together to build your AI factory. Well, as AI has gotten a lot more powerful, it's not just enough to have just GPUs anymore. So what we talked about in the keynote was a brand new pod.

So it's the NBL 72 systems, It's our Vera rack as well because agentic AI needs a lot of CPU processing power for all the sandboxing, for all the testing that it does. So I need NVL 72 Vera Rubens. I need racks of Vera systems for all the compute work. And there's a new class of storage that's needed and that's what we did with STX. Very similar to what we did 10 years ago with DGX. We came out with a reference architecture for the industry to accelerate a new form of application. and all this agentic workflow needs high speed storage context that can either store the context of what the workload that you want it to do, it could offload certain things because AI, the power of AI, it needs data. You need to be close to the data.
Power Efficiency
And so we're working with all of our storage partners so that they can take their storage stack, all of our great partners like NetApp and Vast and DDN and HPE, their storage stacks, what they've got decades of investment will run on top of that STX reference architecture, all in that same AI pod. And so as enterprise customers looking to deploy AI, they're not going to buy STX from NVIDIA. They're going to buy that STX design from the storage partners they're already working with today. NVIDIA is innovating on the STX platform to help all of our storage partners to bring better speed, better efficiency, better token economics to that entire pod with the STX design. help me understand what the STX design even enables.
So like from a workload perspective, if I'm thinking about running an AI agent before, I was storing a lot of that context in like high bandwidth memory close to the GPU, right? Now, what does that let me do? Bigger workloads, faster, like help me understand. So all of the above, when you think about the new agentic workloads, it's more beyond, you know, the things that we were doing just even a year or so ago where a job would run for a minute, maybe five minutes. You know, one example that I think we all saw in the news was they had an agentic workload from scratch build a C compiler. Yeah. That took a week.
Now, in that, I couldn't possibly store all that context in GPU memory all at once So I needed something that was very close to the GPU something that was very accelerated to store all that context to move things back and forth So that one very long running use case of it But the other part of accelerating your token economics on that workload, especially in today's storage world with everything that's going on in the market, if I can make your tokens process 5X faster because I'm putting that storage optimized closer to the GPUs, well, I can do 5x more work on the same amount of storage that I just bought. That's right. And so it's not only great for our storage partners, but it's great for our customers who are trying to put all these things in their data center.
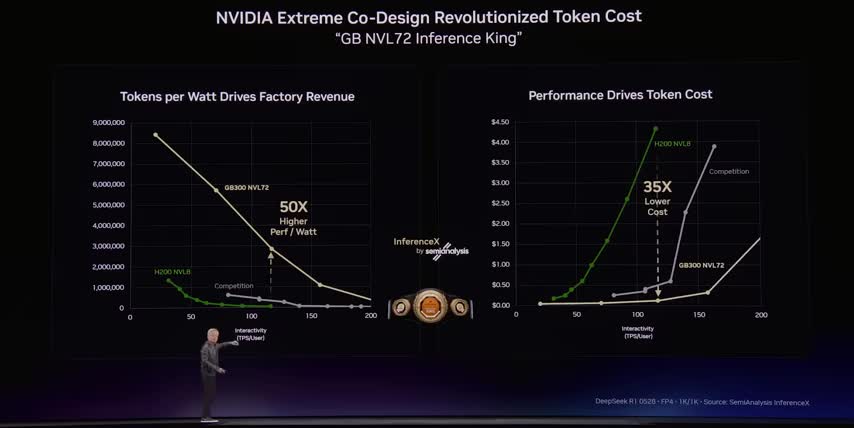
Less physical infrastructure means it's more power efficient, means I can use more power for processing. It's lower cost because I can get more work done with the same physical footprint. So all in all, it's a win-win, but it all builds in that same pod architecture. Yeah, speaking of which, so power efficiency, I think is something I'd love to talk to you about. During the keynote, there was a lot of talk about Vera, the CPU, and Rubin, the GPU. Help me understand how those two new architecture, like the new Vera Rubin architecture affects the DGX systems going forward. What is the performance jump from the Blackwell version of DGX to the Vera Rubin version of DGX? So, as Jensen put it up in the keynote, 35X on agentic workloads.
Now the funny thing is, because last year we had a 35X as well, and even talked about in the keynote, the semi-analysis, when they ran it, it was 50X. What did they say? They said, Jensen, you're sandbagging. What's funny is most people think when we put out those numbers, like that's the most cherry-picked number possible out there. But I see real numbers like that from customers. Even in the hopper to Blackwell generation, I had a customer that was seeing a 50 to 100X speed up, And for them, that meant for the same system they had, they could get 50 more clients on that same infrastructure. Whoa! So they could serve more customers, bring more people on board at the same cost, the same power efficiency, and so when you see that 35X in Vera Rubin, you can take that in two ways.

Like, I can do more work faster, or I can save a lot of money. And most of our customers do both. And a big thing that Jensen talked about towards the end in the new DSX gigascale AI factory. He talked about dynamic power and max-q. And now most of the people watching this today aren't going out and building a gigascale AI factory tomorrow, right? But, you know, I've been in the data center industry for more years than I care to remember at this point, but in many decades. But what does everyone do in a data center when you're building it? You provision for the power that's on the nameplate on the back of the server. And what that does is you're over-provisioning the power because your entire racks and racks of systems are never running at 100% all at the same time.
But for safety reasons, everyone says, well, no, it could happen. And humans can't turn the knobs fast enough if everything does happen hit at the same time. So that's what we talked about in the new DSX design for GigaScale, but that translates all the way down to a customer buying two racks of NBL 72. It's that dynamic power management that you just tell it how much power you have available to you and if one rack is using, you know, both racks are using 100% of that, great. If one of the racks isn't using all of that, it can speed up the other rack. And because that's AI built into the chip, built into the power management, brand new in Vera Rubin, because it's both the CPU and the GPU working together, that power sloshing, I can make every watt I pay for turn into real tokens.

Whereas today, anyone would tell you with over-provisioning, the average is 60% of the energy coming into the data center is actually doing useful work. That other 40% is over-provisioned, it's heat loss, it's all those other things, because nobody ever felt safe pushing that limit because there weren't automatic controls. And that's brand new in the Verirubin architecture. It starts with a chip, it goes all the way through the software, the telemetry, so that as a customer, you set that number, We put things in the power systems, capacitors, everything needed so that you can feel safe for that. So you're getting the value out of every watt you're spending.
So it's not just a 35X improvement in terms of performance, but it sounds like there's also like a 67% improvement in the amount of power you can use that you had provisioned, right? From that 60% all the way to the 100%. Yeah, and because any data center operator would tell you like, oh my God, if you hit 100%, bad things happen today. Sure, yeah. But if I can have those automatic controls and I can believe in it, and that's why we're investing. Sorry, Jen, not only that pretty picture that you saw of DSX in the render, in the simulation, that being built in Northern Virginia So we going to build that and run that for our own use but that same design we can show customers not only that it works on paper but that we running that 24 at 100 and when the public utility says, hey, I need you to not be at 100%, they can send us a signal, and the system automatically reacts to that.

So it's not only what we do in the data center, everyone's talking about worldwide power, that the interfaces, the things that we're pioneering in there aren't just for our own things, like, hey, it's hot, People need more air conditioning in their house. Hey, data center, can you turn it down a little bit? They send the signal and it automatically works and we're still optimizing the work coming out of those. Wow, I feel like that's really slept on. I didn't hear, I certainly didn't hear enough about that in the keynote, so I'm really happy you highlighted that. I think that's a really huge benefit to, especially since most data centers are power constrained today, right? Yeah, no matter what size you are, you only have so much power.
Future of AI
Whether it's your home, you know, whether it's your data center, like you've only got so much power, but at a data center level, However much power you pay for, whether you use it all or not, you're still paying for it. And so that's the tremendous advantage in the Vera Rubin generation. We had to put a lot into the hardware itself. We had some of it in the Blackwell generation. We could smooth things out a little bit. We talked about that last year. Yeah, we talked about it last year. That was a new innovation in the PowerShell. But now it's all the way from the chip to the PowerShell to the rack to the data center. That's huge, that's huge. I think that's a feature that I'd love to talk more about, but one of the things I want to ask, just because I know we're short on time.
So 10th year of DGX, 20th year of CUDA, you've seen this system evolve so much over generation after generation. Is there another feature that you're like really proud of, really pumped to talk about, you know, that you've seen evolve sort of from the ground up? I don't, it's less of a feature in the system, it's how our customers use these. Because the biggest thing, and one of the things, I've talked to people about this in the past, but it's still true today. Every system we put out, within a year of putting that system out, just in software, the system usually gets up to 2x faster. Right. Which is like completely opposite of consumer electronics. Like your phone gets slower every year. Yeah, right.
But because the optimizations that we do in CUDA and because it's just talking about 20 years of CUDA, it's application compatible. That very first DGX1 that was running on the show floor here 10 years ago, the application that was running on that would run on this thing today. So like when Nvidia releases a Tensor RT LLM update that makes it twice as fast as inference. Yeah. All of these, regardless of the generation, yeah. Everyone gets it in that generation. And, you know, that's something, you know, it's a little bit of the unsung here. Our customers talk about it. But it's one of those things that, like, you can't see on day one. The numbers that we put up in the keynote, fantastic numbers today.

When we revisit that six months from now, nine months from now, they're just going to get better. and I guess from a feature perspective, it's not a feature that I'm looking forward to, it's all the new things that our customers are doing with this agentic workload. We talked about OpenClaw and doing it safely. That is the most exciting thing as just a general technology user. I'm sure you've had this idea, I've definitely had the idea of like, oh I wish I had a program that could do X. It's just an average everyday user where I'm like, I could probably code that or I could call a friend, But it's like, nah, I never do that. But now that we can safely take OpenClaw, build a software application on Sandbox, we're doing that actually in the park.
We got OpenClaw and Stallfest with safe software to help people build their own applications. That's the thing that's exciting me the most is that everyone at this show, everyone at home, every business user that ever had an idea that used to say like, hey, I wish I had a little software application that did X. Well, if you can think about that now, With the technology that's available today, you can make that happen. So, you know, that's super exciting now. And what I can't wait for is, like, next year, everyone's showing the examples of, like, what they did on their systems that they got from us this year. Like, what was new and unexpected that, like, nobody thought of that, like, changed the way they did their day-to-day work or their day-to-day life. I'm super excited for that.
Charlie, thank you so much for your time. A huge thank you to Charlie for walking us through NVIDIA's DGX systems. systems, their role in the AI revolution, and the huge gains from Blackwell to Rubin. 35 to 50x performance in a single generation redefines what's possible across training, inference, and opens the doors for entirely new kinds of AI workloads. And to me, that's a future worth investing in. Thank you to the NVIDIA team for flying us out to California, for supplying us with press passes for GTC, and for making this interview possible. And of course, thank you for watching and supporting the channel. Without you, I would never get these kinds of opportunities in the first place. And if you want to see what else I'm investing in, check out this video next.
Either way, thanks for watching and until next time, this is ticker symbol you. My name is Alex reminding you that the best investment you can make is in you.
Key Takeaways
The key takeaways from this interview are:
- The NVIDIA DGX system has evolved significantly over the past 10 years, with a focus on making AI easy to use and delivering business value to customers.
- The Vera Rubin architecture provides a significant performance boost, with 35-50x faster performance and improved power efficiency.
- The DGX system is designed to be a reference architecture for the industry, allowing partners to build their own AI systems.
- The Bluefield 4 STX reference memory architecture enables faster and more efficient storage, allowing for bigger workloads and faster processing.
- The future of AI is exciting, with new technologies and innovations emerging all the time, and the potential for AI to revolutionize industries and improve people's lives.
Checkout our YouTube Channel
Get the latest videos and industry deep dives as we check out the science behind the stocks.